


The accounts payable function has, for decades, been one of the most labour-intensive backrooms in enterprise finance. Hundreds of vendors, thousands of invoices per month, dozens of different formatting conventions, variable layouts, scanned PDFs, email attachments, and portal downloads. Processing this reliably and at scale has resisted automation precisely because traditional tools were built for consistency — and vendor invoices are stubbornly inconsistent.
The arrival of multimodal large language models with vision capabilities has changed this equation fundamentally. But how much, exactly? What do the actual performance benchmarks show? And what architecture should a CFO or CTO choose in 2025-2026?
Why Traditional OCR Templates Break at Scale
Traditional OCR engines — including market leaders like ABBYY FineReader and legacy Kofax implementations — operate on a fundamentally geometric premise. They map field extraction to specific pixel coordinates or text regions within a document. When Vendor A delivers their invoice with "Total Due" in the lower-right quadrant, the OCR template extracts correctly. When Vendor A's design team refreshes the invoice template and moves "Total Due" four centimetres to the left, the template silently fails — extracting an empty field, or worse, extracting the wrong numerical value.
At scale, this is catastrophic. Organizations processing 10,000+ invoices per month will have hundreds of vendors who periodically update their invoice layouts. The overhead of creating, testing, and maintaining OCR templates for each vendor and each layout version can consume more human hours than simply processing the invoices manually — defeating the purpose of automation entirely.
"Traditional OCR systems can achieve up to 99% accuracy on documents with unchanging layouts. Performance degrades significantly when faced with variable formats or lower-quality documents, as they rely on templates and predefined rules that break with any layout change." — AI Multiple, 2024 Document Processing Benchmark
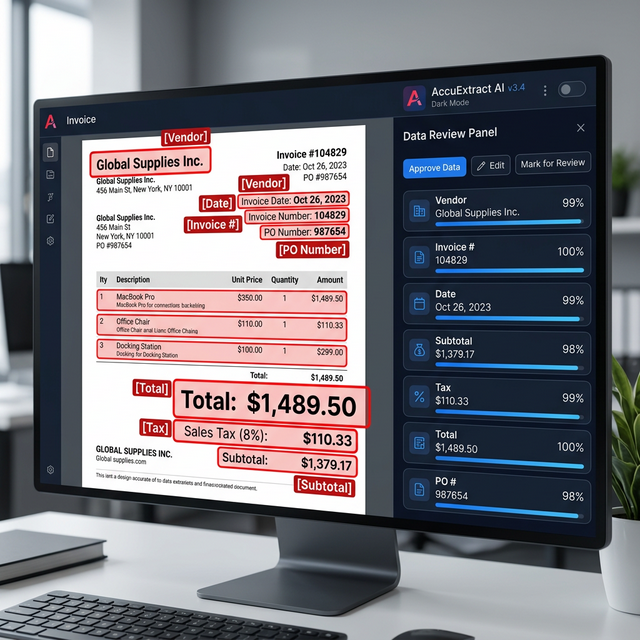
The 2024–2025 LLM Benchmark Results
Comprehensive benchmarking across major AI platforms, conducted in 2024 and early 2025, paints a nuanced picture of LLM performance on structured document extraction tasks.
Key Benchmarks: 500-Invoice Study
Claude Sonnet 3.5: 90% field-level extraction accuracy on a diverse corpus of 500 invoices. Demonstrated particular strength on complex multi-page invoices and maintained consistent performance even on lower-resolution scans. Notable for producing consistent, valid JSON output — critical for automated pipeline integration.
GPT-4o (with third-party OCR preprocessing): 91% accuracy in the same study. Emerged as a top performer specifically when combined with dedicated OCR for raw text extraction, with the LLM then providing semantic mapping and field reconciliation.
Gemini 2.5 Pro: 96.50% accuracy on clean invoices; 92.71% on scanned documents. Led the benchmark on many structured field categories, attributed to strong integrated vision capabilities that process text and imagery simultaneously without a separate OCR preprocessing step.
Dedicated OCR/IDP (e.g., Veryfi): 98.7% overall accuracy in a 2025 benchmark, with strong performance on vendor names (99.2%), amounts (99.1%), and dates (98.9%). Processing speed: 3–4 seconds per invoice.
The performance gap between best-in-class LLMs (96–91%) and best-in-class specialized IDP (99%) is somewhat misleading without context. Specialized IDP platforms require significant upfront template configuration and ongoing maintenance to sustain their accuracy figures. LLMs achieve their accuracy with zero template configuration — they generalize across formats without requiring a vendor-specific setup.
The Real Limitation: Hallucination Risk on Financial Data
The primary risk that makes enterprises cautious about deploying LLMs for invoice parsing is a fundamental property of transformer-based models: hallucination. An LLM can confidently produce an incorrect value — and unlike an OCR engine that will simply return an empty field when it fails to find text, an LLM may manufacture a plausible-looking number.
For financial automation, this is unacceptable without mitigation. Paying the wrong amount, to the wrong vendor, with the wrong payment terms, is a compliance failure that carries real consequences. The architecture must account for this.
The solution is a deterministic validation layer: a separate computational step applied after LLM extraction that performs mathematical verification independent of the language model. If the sum of extracted line items does not match the extracted subtotal to within a configurable tolerance, the invoice is automatically flagged and routed to a human reviewer — regardless of the LLM's confidence. This validation step is implemented outside the LLM entirely, using conventional arithmetic, and cannot be hallucinated.
The Recommended Hybrid Architecture for 2026
Based on the benchmark data and real-world enterprise deployments, the optimal architecture for invoice processing at scale is:
- Stage 1 — Document Ingestion: Normalize inputs (PDF, image, email attachment) into a consistent format. Apply PDF text extraction where documents are born-digital. For scans, apply a cloud OCR service (AWS Textract or Google Document AI) for raw text extraction.
- Stage 2 — Semantic Field Extraction: Pass the raw text to a designated LLM (Claude Sonnet 3.5 or GPT-4o) with a structured extraction prompt specifying the required JSON schema: vendor name, invoice number, invoice date, due date, line items array, subtotal, tax, total.
- Stage 3 — Deterministic Validation: A Python script performs mathematical verification — does the sum of line items equal the subtotal? Does subtotal plus tax equal total? Any mismatch routes to human review. Pass-rate from well-implemented systems exceeds 97% on clean corpora.
- Stage 4 — ERP Integration: Validated invoices are written directly to the ERP (NetSuite, Xero, SAP, QuickBooks) via API. No human touchpoint unless the validation fails.
Citations & Reference Sources
Want to implement this in your business?
Book a free discovery call with Pratik directly. We'll map out where LLMs and robust automation can generate the highest ROI in your existing processes.